
If you have ever build a machine learning model, you already know that finding the right hyperparameters is crucial for delivering accurate models.
To recap, you need to fuss over two types of parameters:
- Model parameters — all the performance tidbits you learn when training your model (e.g. optimal weights in Neural Networks).
- Hyperparameters — the “unknown” values programmed by the user before starting training (e.g. number of estimators in Random Forest).
In this post, we lined up several working techniques for optimizing hyperparemeter selection. Let’s dig in!
- Optimize by Learning Rate
Learning rate is the cornerstone hyperparameter you can tune since it helps you get a well-trained model faster. But going too fast means also increases the loss function. And that’s not great. So your goal is to ensure that it stays in check too.
As per usual, you have several options to tune the learning rate for DL and ML models:
- Rely on a fixed learning rate. Test a range of possible values and analyze the changes in the loss. Identify the fastest rate that doesn’t improve the loss. This is a bit of a trial-and-error solution. But it can work well if you already have good benchmarks for similar models.
- Sequential optimization. Start with a faster rate — then switch to a slower one, once you’ve had some fine-looking results. When do you switch? There are two good options. First, you can monitor the improvements in the loss function. Once you get to a halt, decrease the learning rate. Alternatively, you can adjust the learning rate in line with the training time.
- Stop-start optimization. Since a faster rate yields better results, why not switch a couple of times? By jumping between fast and slow learning rates, you can avoid local optima.
2. Try Dropout Regularization
More complex models are prone to overfitting the training data when trained on small data samples. Instead of learning, such models plainly memorize data and thus, delivered subpar results when given new data.
Dropout method, proposed by Nitish Srivastava et al. in this paper, is aimed at regularizing the training of multiple neural networks with different architecture.
The team proposed to “drop out” some of the layer outputs at random to make the training process less noisy. Because nodes in the same layer will be forced to share responsibility for inputs in a probabilistic way.
Jason Brownlee published a great guide, detailing how to use the dropout method for tuning your models.
3. Try K-Fold Validation
K-Fold validation is a statistical method of estimating model performance on new data (and finding ways to improve it). Used for cross-validation, this approach can help you gauge how well the model will perform with unseen data.
Here’s how it’s done:
- Randomize the datasets
- Split it into k groups
- Divide k groups into test and training datasets
- Run the training and testing
- Collect the evaluation score
As you’ve might have guessed, choosing a good k value is very important. First, ensure that your k value is representative — it’s large enough to be statistically representative of the entire dataset, not just individual test/train data samples.
You can also go with k=10. This option has been experimentally confirmed to result in a model skill estimate with low bias.
Alternatively, you can use k=n, where n equals the size of the dataset. This way you provide each test sample an opportunity to be used in the training dataset. This is also known as leave-one-out cross-validation.
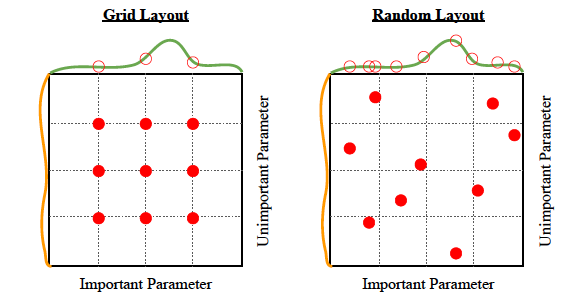
4. Try Random Search Algorithm
The name is a giveaway here. To optimize your model, you can test-drive a bunch of random hyperparameters from a uniform distribution over some hyperparameter space. Keep the winners, toss the underperformers.
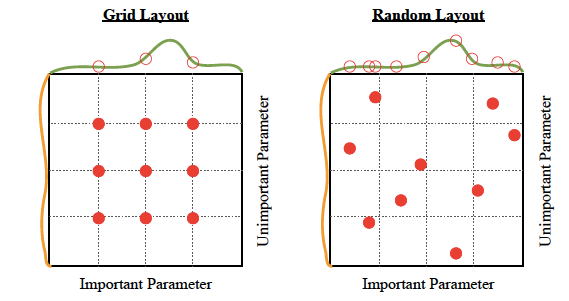
It’s a simple hyperparameter tuning approach, but it can drive good outcomes as illustrated above. It can be parallelized too. Still, it’s pretty resource-heavy and may not move the needle in terms of model performance.
5. Use Bayesian Hyperparameter Optimization
In contrast to grid search, Bayesian optimization relies on “knowledge” obtained during earlier interactions of your model.
This model relies on the “surrogate” of the objective function (p(y | x)), which is easier to optimize. In essence, this method tries to determine which set of hyperparameters could work for optimizing the objective function by analyzing what works best on the surrogate.
Here’s how to approach Bayesian hyperparameter optimization:
- First, you’ll need to create a surrogate probability model of the objective function
- Find which hyperparameters work best (using the above methods, for instance)
- Apply them to the objective function
- Upgrade the surrogate model with new findings
- Interate a couple more times till you hit max iterations or time
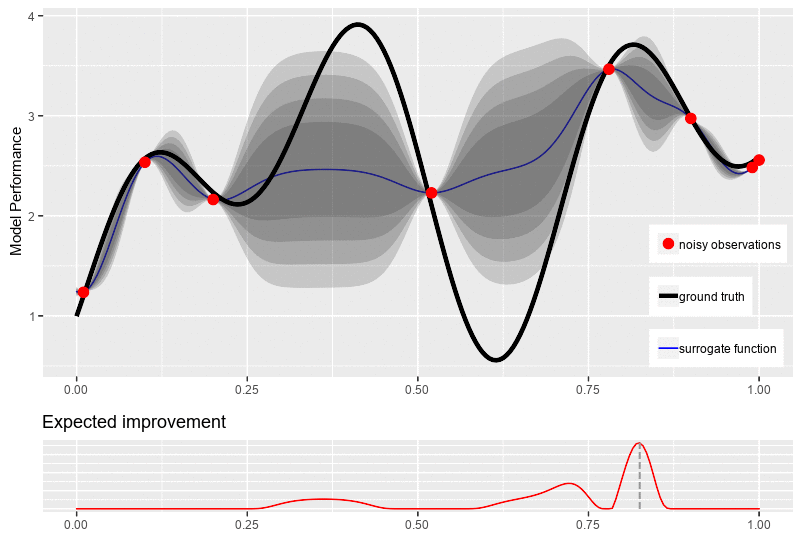
Generally speaking, Bayesian optimization is effective because you choose hyperparameters in an informed manner. But this option has certain shortcomings too.
To Sum Up
Hyperparameter tuning is a scientific art — you gotta be analytically creative to peg down the optimal approaches and values. But then again, there’s no real “shortcut” to developing highly accurate machine and deep learning models from the get-go.





{kind=link}