A popular engineering joke says: when you are raising money for a project — are selling AI. When you are marketing your project — it’s machine learning and deep learning. And when you are actually doing the job — it’s PyTorch, decision-trees, and backpropagation all day long.
Machine Learning vs Deep Learning: the Lowdown
Source: IBM
What is Machine Learning?
Machine learning is an umbrella term for all algorithm methods for training software systems to self-learn and achieve the stated outcome by analyzing the provided data.
In layman’s terms, ML is a method for giving a computer the “smarts” to pass its judgment on the provided information.
A very simple example of machine learning will be providing the algorithm with a set of cat and dog pictures and training it to distinguish between the two.
What is Deep Learning?
Deep learning is a subset of machine learning that enables machines to be taught by example.
DL relies on more complex algorithms — e.g. artificial neural networks — to enable multi-step data interpretation scenarios. Each training layer assesses the data from a different perspective, draws a conclusion, and passes the knowledge to the next layer, all the way till the final decision is made.
In that sense, deep learning is better suited for more complex machine learning use cases. Going back to our example, a DL algorithm can receive a dataset of cat and dog pictures with no labeling (it doesn’t know who’s a dog and who’s a cat). By analyzing different features of each animal, such algorithms can independently figure out what the animal looks like, and label all pictures accordingly.
Machine Learning and Deep Learning: Main Differences
The main difference between machine learning and deep learning is in how each algorithm learns.
- Machine learning algorithms require labeled datasets to get trained for understanding the differences between A and B. You train such algorithms using supervised learning — the algorithm maps an input to an output based on example input-output pairs (labeled data in your dataset).
- Deep learning algorithms can be trained with labeled and unlabeled data sets. Or just unlabeled data. The latter is called unsupervised learning — the algorithm attempts to find its own structure for labeling data and learn, based on those observations.
In essence, deep learning attempts to mimic the way the human brain learns — by example, with an occasional prompt.
Understandably, that’s not a straightforward task. Thus, there are many different ways to prompting that learning experience.
Machine Learning vs Deep Learning Methods Comparison
| “Classic” Machine Learning Methods | Deep Learning Methods |
| Linear regression | Classic neural networks |
| Logistic regression | Convolutional neural networks |
| Naive Bayes classifier | Convolutional neural networks |
| Random forest | Recurrent neural networks |
| Decision tree | Generative adversarial networks |
| K-Means | Backpropagation |
Data Requirements for Machine Learning and Deep Learning
The second difference between machine learning and deep learning is the data format, volume, and quality required to reach a high accuracy of algorithm performance.
- Machine learning always requires labeled structured data.
- Deep learning is feasible with a mix of labeled and unlabeled data (structured or unobstructed). Or unlabeled data only for certain methods.
In both cases, data quality will be detrimental to the algorithm’s performance and accuracy.
However, deep learning algorithms have a higher tolerance for impartial, incomplete data as they parse it through hierarchies of different concepts during the training phase. Such a multi-stage approach allows DL algorithms to ‘self-fill-in’ the gaps in knowledge and derive accurate results. On the other hand, the algorithms may base their judgments on the wrong parameters.
A group of scientists from the University of Washington has been training a neural network to identify dog vs wolf. All the pictures of wolves had snow in the background, whereas dog images often had something else. The neural network picked that up and labeled all pictures with a light background as those of wolves, even if that wasn’t true.
Finally, data volume will play a role too. Machine learning algorithms are best trained on smaller data sets (since all data requires labeling). So they are not always easy to scale. Deep learning algorithms, on the other hand, can be used to operationalize larger datasets.
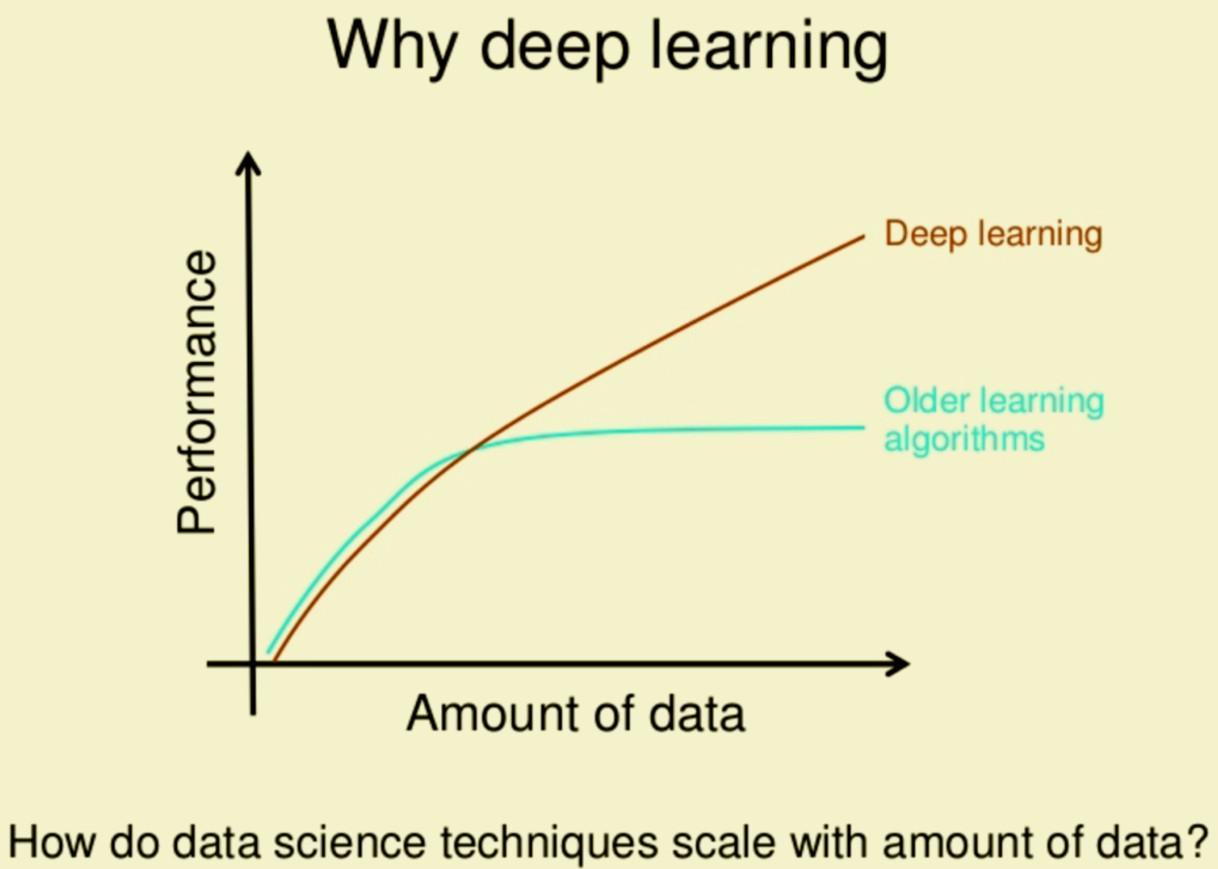
Source: Medium
That’s a pro and a con. Since such algorithms will always require more data (+ time, computing resources) to be trained effectively. This leads us to the last difference.
Hardware Requirements for Machine Learning and Deep Learning
Deep learning algorithms require significantly more computing resources for training than machine learning algorithms.
While a small-scale, yet highly effective machine learning algorithm can be trained on local CPUs, most deep learning use cases will require more robust graphics processing units (GPUs). That makes the training costs steeper.
The good news is that the commoditization of machine learning and deep learning has also led to the rise of supporting services and infrastructure. For example, you can rent cloud GPU units on-demand to run your experiments from Neu.ro — a managed MLOps platform, providing end-to-end technical infrastructure for ML/DL projects — or a host of other providers.
To Conclude: Which is Better: Machine Learning or Deep Learning?
It depends on your goals and use case. If you have a limited labeled dataset and a concrete problem statement you want to tackle, machine learning is the best way to go. Deep learning will be better suited for more complex projects, where you lack the knowledge for feature introspection, have a large dataset to work with, and supporting infrastructure to run your experiments.





